_edited.png)


The end of spreadsheets? How coding is transforming how we work
- Stephen Gruppetta

- Jul 5, 2022
- 3 min read

In a recent Python course I ran in the City, as we often do on the final day of a Python coding three-day training course, I asked participants to bring along some of their work. They had to choose something they are working on which they believe could be done better and more efficiently with programming.
I'll keep the details very vague for obvious reasons. I was given a spreadsheet with about 57 columns and hundreds of rows. Each column was a time series for a different market and the team wanted to explore relations between these markets using mathematical tools such as cross-correlation. Of course the team were very competent with the maths they needed and they understood their data extremely well, as you would expect from such a highly skilled team in a leading international financial institution.
The problem they wanted to solve was one of efficiency. Although by the end of the day they realised that there were even more answers to be found beyond simply a gain in efficiency. Most of the time went into collating the data into one spreadsheet, ensuring the correct format since data were obtained from different sources, and once the mathematical operations were performed they wanted to plot graphs. Mastery in Excel helps, of course, but there are limits to what one can do in Excel, and even more limits to the patience required to perform more involved tasks in Excel.
This was a perfect example to introduce some of the key topics in quantitative programming. Firstly, all the data was available from sources that offered API access - this means that the data can be read directly from a computer program via the internet, automatically. We can them move on to make sure the formatting of dates and numbers is the same: a few lines of code will do the trick.
Next, we need to put the data into the spreadsheet, except we're not using spreadsheets of course. This allowed us to introduce some advanced data types such as Pandas that allow us to store data in a tabular form as well as perform many mathematical operations across the data in a relatively easy way.
And finally we could introduce plotting modules in Python to present the data in whichever form we want.
Throughout this session (and this happens in many similar sessions) I could see the participants' expressions of wonder at how some code that took a mere 100 lines and not too long to write would from now on, on a daily basis, perform in a few milliseconds what took them much longer to complete. They never actually told me how long each day they spent on this task.
What was just as eye opening for them was a discussion they had during the overdue coffee break which followed. They were wondering whether there were other relationships within their data they could explore which up until then they had assumed were too difficult and time-consuming. Having seen how much easier it is to import and manipulate data from within a Python script, questions that they didn't dare ask of their data suddenly were worth asking.
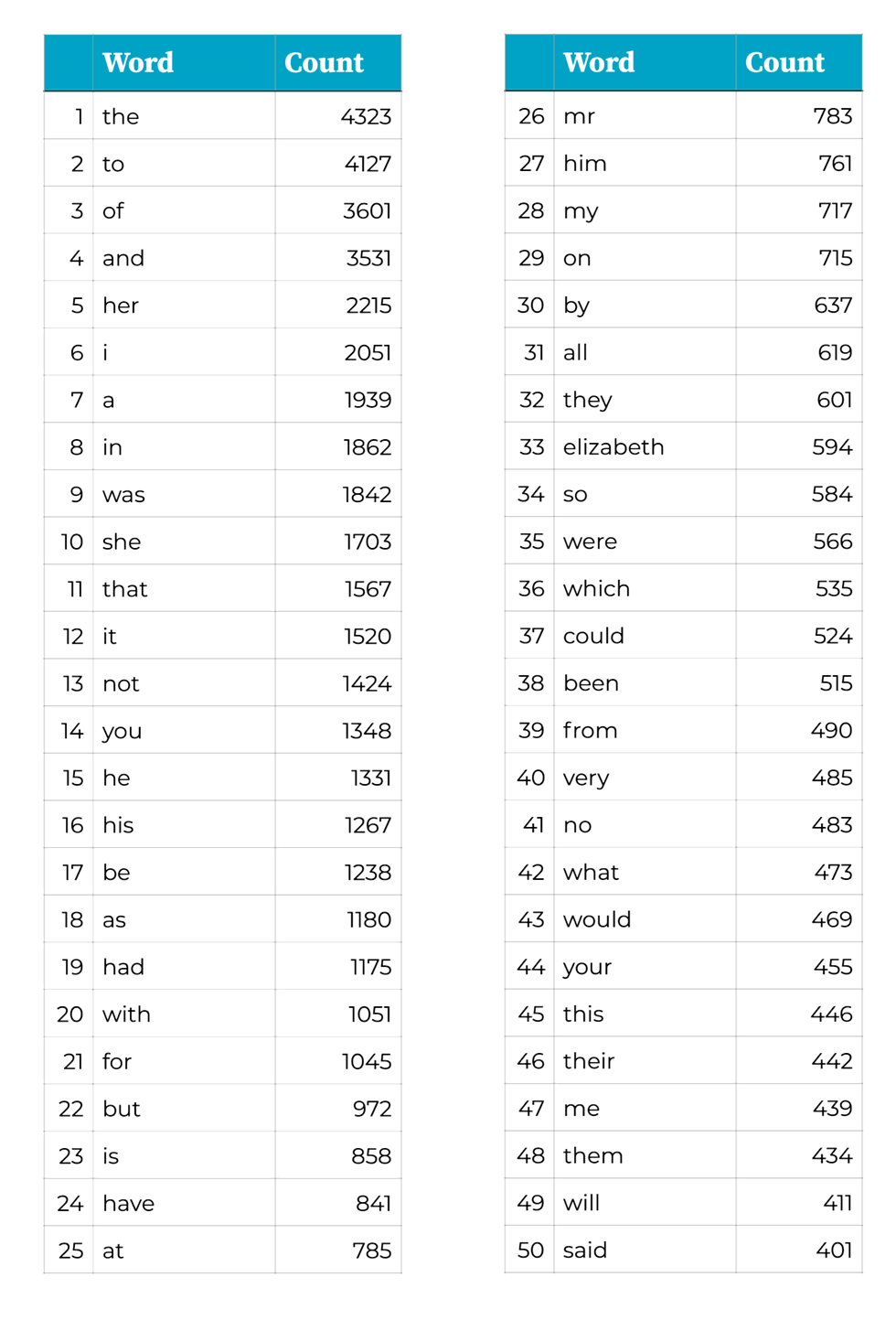
What are all the words that Jane Austen used in Pride and Prejudice, and how often did she use each one?
Not quite a spreadsheet task but this is one of my favourite exercises when teaching some courses. For a human, this is a very simple, yet tediously long, task. Go through the book and write down each new word and keep a tally of how often it's been used. Often, coding is about getting the computer to perform a task that a human could do, only much faster.
And what's great about writing code to do a task is that once you've written the code, you can just re-use it for different data. War and Peace, anyone?
If you're curious, the 30 lines of code or so to perform this task comes up with the following Top 50 words in P&P, with some very predictable ones in the top spots.
Do you spend too much time on spreadsheets and wonder whether investing time to learn coding may save you time, energy and money in the future?
We run our Programming in Python courses, aimed for beginners, throughout the year. We also run a follow-up course focussing in using Python for quantitative applications.






Comments